Spring Data es un proyecto perteneciente a la extensa familia de Spring Framework. Facilita la explotación de almacenes de datos, con una praxis común para todos los tipos de almacenes contemplados. Estos incluyen las omnipresentes bases de datos relacionales, pero también algunas bases de datos NoSQL, como MongoDB o Cassandra; directorios LDAP; y un generoso etcétera.
En este artículo te explico las funciones básicas del módulo de Spring Data para Jakarta Persistence (JPA). Este módulo provee una capa de abstracción sobre JPA que revoluciona la manera de trabajar con las bases de datos relacionales.
Descubrirás lo poco que necesitas para programar la persistencia de tus proyectos basados en Spring; tan poco que apenas escribiremos código. Define tus consultas y Spring Data JPA se ocupa del resto.

IMPORTANTE. Pese a su gran extensión, este artículo apenas ofrece una visión lejana de un enorme lienzo. Te muestro todo el cuadro en este curso:
Asimismo, mi curso gratuito sobre Jakarta EE contiene más de veinte capítulos dedicados a JPA e Hibernate.
Este artículo asume que ya tienes unos conocimientos básicos de Spring y JPA.
Contenido
- Proyecto de ejemplo
- El primer repositorio
- Cómo definir y ejecutar consultas
- Tipos de resultados
- Ordenación
- Paginación
- Operaciones de actualización
- Consultas SQL
- Probar el repositorio con tests automáticos
- Conclusiones
- Código de ejemplo
Proyecto de ejemplo
Aviso sobre versiones
Spring Boot 3, Spring Data 3 y Spring 6 pasaron de las especificaciones JEE a las especificaciones Jakarta EE. Estas últimas son la evolución de JEE. El cambio más significativo es que los paquetes de JEE denominandos javax, en Jakarta EE se llaman jakarta. Tenlo en cuenta cuando trabajes con versiones antiguas de Spring.

Modelo de entidades \ tablas
Lo importante para seguir este artículo es el modelo de clases de tipo entidad, pues las consultas se escribirán para ellas. Tenemos dos clases vinculadas por una relación unidireccional que modelan un país y su posible confederación futbolística:
package com.danielme.demo.springdatajpa.model;
import jakarta.persistence.*;
import java.time.LocalDateTime;
@Entity
@Table(name = "countries")
public class Country {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, unique = true)
private String name;
@Column(nullable = false)
private Integer population;
@Column(updatable = false, nullable = false)
private LocalDateTime creation;
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(name = "confederation_id")
private Confederation confederation;
public Country() {
super();
}
public Country(String name, Integer population, Confederation confederation) {
super();
this.name = name;
this.population = population;
this.confederation = confederation;
}
getters y setters...
package com.danielme.demo.springdatajpa.model;
import jakarta.persistence.*;
@Entity
@Table(name = "confederations")
public class Confederation {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, unique = true)
private String name;
public Confederation() {
super();
}
public Confederation(Long id, String name) {
this.id = id;
this.name = name;
}
getters y setters
Cada clase modela una tabla. Las tienes en la siguiente imagen.

Configuración del proyecto
Tenemos dos alternativas para crear un proyecto basado en Spring Framework:
- Spring Boot. Entre otras ventajas, simplifica la gestión de las dependencias, realiza configuraciones automáticas y ofrece algunas funcionalidades exclusivas. Si no conoces Spring Boot, te recomiendo este tutorial.
- Sin Spring Boot. Es decir, crear y configurar a mano, o con plantillas, el proyecto.
Con Spring Boot
Tienes explicado un proyecto construído con Spring Data JPA y Spring Boot en el curso. En pocas palabras, para incorporar Spring Data JPA a un proyecto basado en Spring Boot basta con añadir al pom el driver JDBC de tu base de datos y el iniciador (starter) llamado spring-boot-starter-data-jpa, y configurar la conexión a la base de datos en el fichero application.properties. La magia de Spring Boot hará el resto.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
spring.datasource.url=jdbc:mysql://localhost:3306/countries
spring.datasource.username=user
spring.datasource.password=password
Sin Spring Boot
Aun cuando Spring Boot es sin duda la mejor forma de trabajar con Spring, crearé el proyecto de ejemplo sin él. Lo cierto es que creé el proyecto cuando todavía no existía Spring Boot —la primera versión de este artículo data de 2014— y he decidido mantenerlo así para ofrecer un ejemplo de configuración manual.
Vamos a partir de un proyecto Maven. Primero agregamos las dependencias al fichero pom:
- Spring Data JPA. Utilizaremos la versión 3.1.1 (precisa Java 17), dependiente de Spring 6.0.10.
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>${spring.data.jpa.version}</version>
</dependency>
- JPA es una especificación —la definición de un conjunto de APIs—, así que necesitamos un producto (provider) que la implemente. Importamos Hibernate, el provider más popular, en su versión 6.2.5. Es compatible con JPA 3.1.
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>${hibernate.version}</version>
</dependency>
- El controlador (driver) JDBC de la base de datos, en nuestro caso MySQL 8.
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>${mysql.version}</version>
</dependency>
- Un pool de conexiones JDBC de alto rendimiento, como c3p0, para que el proyecto sea más realista.
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>${c3p0.version}</version>
</dependency>
- Con respecto a la bitácora (logging) suelo usar log4j. Por eso voy a incluir el adaptador de slf4j que envía a log4j los mensajes de Spring.
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4jlog4j.version}</version>
</dependency>
Configuremos Spring de dos maneras: con los clásicos XML, en claro desuso, y con clases Java. Esta configuración es similar a la que explico en el tutorial Persistencia en BD con Spring: Integración JPA, c3p0, Hibernate y EHCache, así que seré breve.
El componente fundamental es el gestor de entidades (EntityManager) de JPA. Lo creamos para Hibernate a partir de la fuente de datos (un pool de conexiones a un MySQL) y un gestor de transacciones. Los parámetros de configuración se externalizan en el fichero db.properties. En cuanto a Spring Data JPA, indicamos la ubicación de los repositorios que en breves momentos vamos a crear.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.0.xsd
http://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa-1.8.xsd">
<jpa:repositories
base-package="com.danielme.demo.springdatajpa.repository"
/>
<!-- Autowired -->
<!-- used to activate annotations in beans already registered in the
application context (no matter if they were defined with XML or by package
scanning) -->
<context:annotation-config />
<!-- scans packages to find and register beans within the application
context. -->
<context:component-scan
base-package="com.danielme.demo.springdatajpa" />
<!-- enable @Transactional Annotation -->
<tx:annotation-driven
transaction-manager="transactionManager" />
<!-- @PersistenceUnit annotation -->
<bean
class="org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor" />
<!-- classpath*:*.properties -->
<context:property-placeholder
location="classpath:db.properties" />
<!-- data source with c3p0 -->
<bean id="dataSource"
class="com.mchange.v2.c3p0.ComboPooledDataSource"
destroy-method="close" p:driverClass="${jdbc.driverClassName}"
p:jdbcUrl="${jdbc.url}" p:user="${jdbc.username}"
p:password="${jdbc.password}"
p:acquireIncrement="${c3p0.acquire_increment}"
p:minPoolSize="${c3p0.min_size}"
p:maxPoolSize="${c3p0.max_size}"
p:maxIdleTime="${c3p0.max_idle_time}"
p:unreturnedConnectionTimeout="${c3p0.unreturned_connection_timeout}" />
<!-- Hibernate as JPA vendor -->
<bean id="jpaAdapter"
class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter" />
<bean id="entityManagerFactory"
class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"
p:dataSource-ref="dataSource"
p:packagesToScan="com.danielme.demo.springdatajpa.model"
p:jpaVendorAdapter-ref="jpaAdapter">
<property name="jpaProperties">
<props>
<prop key="hibernate.hbm2ddl.auto">${hibernate.hbm2ddl.auto}</prop>
<prop key="hibernate.dialect">${hibernate.dialect}</prop>
<prop key="hibernate.connection.autocommit">${hibernate.connection.autocommit}</prop>
<!--useful for debugging -->
<prop key="hibernate.generate_statistics">${hibernate.statistics}</prop>
</props>
</property>
</bean>
<bean id="transactionManager"
class="org.springframework.orm.jpa.JpaTransactionManager"
p:entityManagerFactory-ref="entityManagerFactory" />
</beans>
La misma configuración en una clase @Configuration:
package com.danielme.demo.springdatajpa;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.PropertySource;
import org.springframework.core.env.Environment;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.orm.jpa.JpaTransactionManager;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
import org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import jakarta.persistence.EntityManagerFactory;
import javax.sql.DataSource;
import java.beans.PropertyVetoException;
import java.util.Properties;
@Configuration
@PropertySource("classpath:db.properties")
@ComponentScan("com.danielme")
@EnableTransactionManagement
@EnableJpaRepositories(basePackages = "com.danielme.demo.springdatajpa.repository")
public class ApplicationContext {
@Bean(destroyMethod = "close")
DataSource dataSource(Environment env) {
ComboPooledDataSource ds = new ComboPooledDataSource();
try {
ds.setDriverClass(env.getRequiredProperty("jdbc.driverClassName"));
} catch (IllegalStateException | PropertyVetoException ex) {
throw new RuntimeException(
"error while setting the driver class name in the datasource", ex);
}
ds.setJdbcUrl(env.getRequiredProperty("jdbc.url"));
ds.setUser(env.getRequiredProperty("jdbc.username"));
ds.setPassword(env.getRequiredProperty("jdbc.password"));
ds.setAcquireIncrement(env.getRequiredProperty("c3p0.acquire_increment", Integer.class));
ds.setMinPoolSize(env.getRequiredProperty("c3p0.min_size", Integer.class));
ds.setMaxPoolSize(env.getRequiredProperty("c3p0.max_size", Integer.class));
ds.setMaxIdleTime(env.getRequiredProperty("c3p0.max_idle_time", Integer.class));
ds.setUnreturnedConnectionTimeout(
env.getRequiredProperty("c3p0.unreturned_connection_timeout", Integer.class));
return ds;
}
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory(DataSource dataSource,
Environment env) {
LocalContainerEntityManagerFactoryBean entityManager = new LocalContainerEntityManagerFactoryBean();
// entityManager.setPersistenceXmlLocation("classpath*:META-INF/persistence.xml");
// entityManager.setPersistenceUnitName("hibernatePersistenceUnit");
entityManager.setPackagesToScan("com.danielme.demo.springdatajpa.model");
entityManager.setDataSource(dataSource);
entityManager.setJpaVendorAdapter(new HibernateJpaVendorAdapter());
Properties jpaProperties = new Properties();
jpaProperties.put("hibernate.hbm2ddl.auto",
env.getRequiredProperty("hibernate.hbm2ddl.auto"));
jpaProperties.put("hibernate.dialect", env.getRequiredProperty("hibernate.dialect"));
jpaProperties.put("hibernate.connection.autocommit",
env.getRequiredProperty("hibernate.connection.autocommit"));
jpaProperties.put("hibernate.generate_statistics",
env.getRequiredProperty("hibernate.statistics"));
jpaProperties.put("hibernate.show_sql", env.getRequiredProperty("hibernate.show_sql"));
jpaProperties.put("hibernate.format_sql", env.getRequiredProperty("hibernate.format_sql"));
entityManager.setJpaProperties(jpaProperties);
return entityManager;
}
@Bean
JpaTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
JpaTransactionManager transactionManager = new JpaTransactionManager();
transactionManager.setEntityManagerFactory(entityManagerFactory);
return transactionManager;
}
}
El primer repositorio
Para cada clase de tipo entidad con la que queramos trabajar, y en vez del tradicional DAO, creamos un repositorio, el concepto sobre el que se sustenta Spring Data. Se trata de una interfaz que especializa a Repository, tipada para la clase de entidad y su identificador:
public interface CountryRepository extends Repository<Country, Long> {
En esa interfaz añadimos métodos que realicen operaciones con la base de datos, siempre relacionados con la clase de tipo entidad asociada al repositorio.
No tenemos que implementar la interfaz. Spring genera para ella un bean en la forma de un objeto proxy. Por consiguiente, inyectamos CountryRepository donde necesitemos sus métodos, tal y como haríamos con cualquier bean.
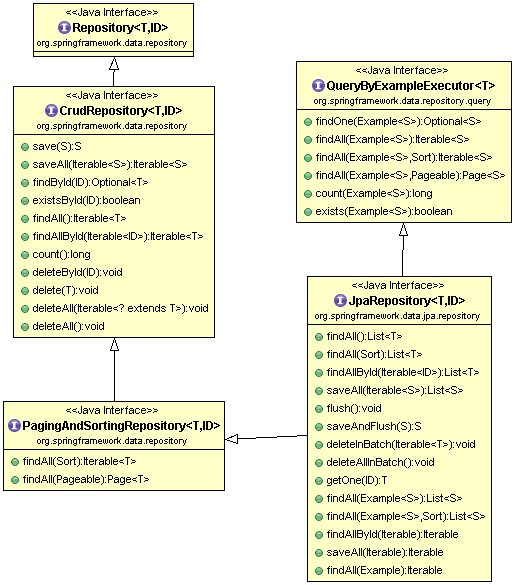
De Repository no heredamos nada, solo informa que una interfaz es un repositorio. Pero cuenta con varios subtipos que podemos especializar a fin de heredar sus métodos, como JpaRepository. Esta interfaz provee las operaciones más habituales, heredadas a su vez de la interfaz de CrudRepository, amén de otras muy ligadas a las peculiaridades de JPA.
package com.danielme.demo.springdatajpa.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import com.danielme.demo.springdatajpa.Country;
public interface CountryRepository extends JpaRepository<Country, Long> {
}
Mucho cuidado: con la herencia de los repositorios genéricos de Spring Data y Spring Data JPA dotamos a los nuestros de algunas operaciones que tal vez no necesitamos. Es más, algunas de esas operaciones pueden ser indeseables. Piensa en findAll, que obtiene todas las entidades de una tacada. ¿Qué ocurre si hay miles? El repositorio de una entidad tan numerosa no debería ofrecer el método findAll, sino una versión del mismo que requiera paginación.
En general, te recomiendo que heredes de Repository. Cuando necesites algún método de los repositorios genéricos, copiálo a tu repositorio. Te aseguro que esta estrategia funciona, pues esos métodos genéricos son en realidad consultas derivadas.
Cómo definir y ejecutar consultas
De momento, CountryRepository no hace nada. Añadamos algunos métodos que ejecuten consultas. A continuación te explico las tres alternativas principales. Hacia el final del artículo también veremos cómo ejecutar SQL.
Consultas derivadas (derived queries)
Estas consultas se definen con una convención para el nombre del método. Spring Data JPA deduce o «deriva» una consulta a partir de ese nombre, que resulta intuitivo.
El nombre comienza con cierto prefijo que indica el cometido de la consulta. Luego le añadimos los nombres de los atributos de la entidad del repositorio por los que queramos filtrar los resultados. Definimos estos filtros con ciertas palabras clave (keywords). Los valores para realizar el filtrado (las variables de la búsqueda) son los parámetros del método.
Se ve claro con ejemplos:
public interface CountryRepository extends JpaRepository<Country, Long>{
Optional<Country> findByNameEquals(String name);
List<Country> findByPopulationGreaterThan(Integer population);
}
El prefijo find informa que el método representa a una …BySELECT. En los tres puntos puedes poner lo que quieras. Los prefijos read…By, get…By, query…By, search…By y stream…By equivalen a find...By.
Despúes aparecen los criterios de selección. En el primer método se trata de la igualdad exacta del nombre del país (Name) con la cadena que recibe el método (String name). En el segundo, la población (Population) ha de ser mayor (GreaterThan) que cierta cantidad proporcionada al método (Integer population).
Esta imagen disecciona el segundo método.

Devolvemos entidades del tipo que gestiona el repositorio. Por lo común, usaremos un Optional si el resultado es único, y una lista en los demás casos. En la próxima sección trataremos este asunto.
La siguiente tabla recopila las palabras claves de Spring Data admitidas por el módulo JPA con las que escribiremos los criterios de selección.
| Keyword | Cometido |
| Equals\Is | Igualdad. Se puede omitir por ser el criterio predeterminado. Por tanto, el método findByNameEquals equivale a findByName. |
| After\IsAfter | Fecha posterior a una dada. |
| Before\IsBefore | Fecha anterior a una dada. |
| Between\IsBetween | Un rango, ambos extremos incluidos. Útil para aplicarlo a números y fechas. |
| LessThan, IsLessThan | Menor estricto. |
| LessThanEqual, IsLessThanEqual | Menor o igual que. |
| GreaterThan, isGreaterThan | Mayor estricto. |
| GreaterThanEqual, isGreaterThanequal | Mayor o igual que. |
| Null, IsNull | Condición de nulidad. |
| Like, IsLike | El clásico operador LIKE de JPQL para las cadenas. |
| Containing, IsContaining,Contains | El operador LIKE, con un matiz: Spring Data JPA envuelve la variable en el comodín ‘%’. |
| StartingWith, StartsWith, IsStartingWith | La cadena debe comenzar por cierto prefijo. |
| EndingWith, IsEndingWith, EndsWith | La cadena debe terminar con cierto sufijo. |
| In, IsIn | La operación lógica IN. Los valores se proporcionan en una Collection, un array o una expresiónvarargs. |
| True ,False, IsTrue, IsFalse | Establece el valor requerido para un atributo lógico. |
| IgnoreCase, IgnoringCase | Se agrega a las expresiones que filtran por cadenas para ignorar la capitalización. |
| Empty, IsEmpty | El operador EMPTY de JPQL, aplicable a las relaciones de tipo múltiple. |
| Not, IsNot | La desigualdad. Puede combinarse con otras expresiones: isNotIn, isNotNull, isNotLike, IsNotContaining, isNotEmpty. |
| And | Encadena varios criterio, de modo que deben cumplirse todos. |
| Or | Encadena varios criterios, pero solo requiere que se cumpla uno. |
Son de especial interés las posibilidades de filtrado de cadenas (Contains, IgnoreCase, Like, StartsWith, EndsWith…).
Veamos un nuevo ejemplo: «busca los países cuyo nombre contenga (Containing) cierta cadena, ignorándose la capitalización (IgnoreCase)»:
List<Country> findByNameContainingIgnoreCase(String name);
Una posible llamada:
countryRepository.findByNameContainingIgnoreCase("p");
Si activas las trazas de Hibernate, configuración ya realizada en el proyecto de ejemplo, verás que la consulta derivada se traduce en esta consulta SQL:
select
...
from
countries country0_
where
upper(country0_.name) like upper(?) escape ?
Advierte que la capitalización se ignoró gracias la conversión de las cadenas en mayúsculas con la función UPPER. También son interesantes las variables de la consulta:
09-19-2020 01:15:56,001 PM TRACE org.hibernate.type.descriptor.sql.BasicBinder:64 - binding parameter [1] as [VARCHAR] - [%p%] 09-19-2020 01:15:56,002 PM TRACE org.hibernate.type.descriptor.sql.BasicBinder:64 - binding parameter [2] as [CHAR] - [\]
Además de atributos de la entidad, en los nombres de los métodos puedes referenciar a sus relaciones. Por ejemplo, esta consulta encuentra países según el nombre exacto de su confederación:
List<Country> findByConfederationName(String confederationName);
¿Necesitas varios criterios de selección? Únelos con And y\o Or:
List<Country> findByNameContainingIgnoreCaseAndConfederationId(String name, Long confId);
El método se lee así: «dame los países cuyos nombres contengan, ignorando la capitalización, la cadena name, y que pertenezcan a la confederación de identificador id«.
Ten en cuenta que el orden de los parámetros debe respetar el orden en el que aparecen en la signatura del método los campos a los que están vinculados. Por ello, en el ejemplo el primer parámetro debe ser el nombre. Debido a esta convención, el nombre de los parámetros resulta irrelevante.
Con el prefijo count…By escribimos consultas que cuentan las entidades que verifican los filtros:
int countByPopulationGreaterThan(Integer population);
Por su parte, exists…By averigua la existencia de algún resultado:
int existsByPopulationGreaterThan(int population);
Analizo las capacidades de las consultas derivadas en el capítulo 5 del curso. Encontrarás muchos ejemplos; por ello no voy a entrar en más detalles. Con todo, te dejo algunos ejemplos adicionales para que te familiarices con este tipo de consultas:
- «Entidades de países creadas entre dos fechas». Aunque la consulta haga referencia a un único atributo de
Country, el método precisa dos parámetros:
List<Country> findByCreationBetween(LocalDateTime start, LocalDateTime end);
- «Países cuyo nombre empiece por cierta cadena, ignorándose la capitalización»:
List<Country> findByNameStartingWithIgnoreCase(String name);
- «Países no asociados a las confederaciones indicadas»:
List<Country> findByConfederationIdNotIn(Long... ids);
¿Te han convencido las consultas derivadas? Son fáciles de escribir; la funcionalidad de Spring Data más sorprendente. Ahora bien, su sencillez tiene como precio dos limitaciones:
- Solo permiten selecciones simples de entidades.
- Pueden originar nombres de métodos demasiado largos y, por ende, de difícil entendimiento. Aunque sea válido, nadie quiere leer
findByNameContainingIgnoringCaseOrCapitalIgnoringCaseContainingOrderByName.
Superamos estas restricciones con JPQL, el lenguaje de consultas de JPA.
Consultas con JPQL
JPQL ofrece parte de la expresividad de SQL aplicada a clases de tipo entidad en vez de a tablas. Asimismo, la implementación que Hibernate ofrece de JPQL, llamada HQL, amplía las capacidades originales del lenguaje.
Cabe mencionar, además, que Spring Data JPA transforma las consultas derivadas en una consulta JPQL que envía a Hibernate. A su vez, esta librería transforma las consultas JPQL en consultas SQL, lo único que entiende la base de datos.
Las consultas JPQL se definen en métodos del repositorio dentro de la anotación @Query:
@Query("select c from Country c where lower(c.name) like lower(?1)")
List<Country> getByNameWithQuery(String name);
Nota. Las consultas JPQL que veremos serán bastante simples y pueden escribirse como consultas derivadas. Lo importante es cómo se usan.
Las variables de la consulta son los parámetros del método. Así, la expresión ?1 se refiere al primer parámetro definido en el método. Pero un nombre es mejor que un número:
@Query("from Country c where lower(c.name) like lower(:name)")
List<Country> findByNameWithQuery(@Param("name") String name);
El código resultante es más legible. Y más seguro, ya que Ahora podemos cambiar el orden de los parámetros sin «daños colaterales».
Si usas los nombres de los parámetros tal cual en la consulta, no necesitas @Param, siempre y cuando indiques la opción -parameters de javac al compilar el código. Esto ya lo hace Spring Boot. De lo contrario, verás una excepción que te lo explica:
org.springframework.dao.InvalidDataAccessApiUsageException: For queries with named parameters you need to provide names for method parameters; Use @Param for query method parameters, or when on Java 8+ use the javac flag -parameters; nested exception is java.lang.IllegalStateException: For queries with named parameters you need to provide names for method parameters; Use @Param for query method parameters, or when on Java 8+ use the javac flag -parameters
En Maven se soluciona así:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>${project.build.sourceEncoding}</encoding>
<compilerArgs>
<arg>-parameters</arg>
</compilerArgs>
</configuration>
</plugin>
Consultas nombradas (named query)
Las consultas nombradas de JPA son consultas JPQL declaradas con anotaciones en una clase de tipo entidad o bien en el fichero /META-INF/orm.xml. Se identifican con un nombre único. Vamos a añadir una consulta de este tipo a la entidad Country:
@Entity
@Table(name = "countries")
@NamedQuery(name = "Country.byPopulationNamedQuery", query = "FROM Country WHERE population = ?1")
public class Country
{
El nombre del método que la ejecuta debe coincidir con el de la consulta, el cual, a su vez, debe tener como prefijo el nombre de la clase entidad del repositorio seguido de un punto. Puesto que el nombre de la consulta es Country.byPopulationNamedQuery, el método asociado será CountryRepository#byPopulationNamedQuery:
Optional<Country> byPopulationNamedQuery(Integer population);
Puedes obviar esta convención e indicar el nombre de la consulta en @Query:
@Query(name = "Country.byPopulationNamedQuery")
Optional<Country> cualquierNombre(Integer population);
Tipos de resultados
Hasta ahora, nuestros métodos devuelven los resultados de las consultas de dos maneras:
- En un objeto, cuando solo pueda existir uno. Recomendable envolverlo en
Optionalsi procede. - Contenidos en una lista, cuando puedan ser varios. Se admite
Collectiony varios subtipos comoSetoArrayList. Existen otras opciones más avanzadas, como envolver los resultados en unFuturesi queremos trabajar de manera asíncrona. Tienes todas las alternativas aquí.
El tipo del resultado es la clase entidad que maneja el repositorio o bien int y boolean en el caso de las consultas de tipo count...By y exists...By. Asimismo, las consultas JPQL pueden retornar cualquier escalar:
@Query("select c.name from Country c where c.id = :id")
Optional<String> findNameById(String id);
Proyecciones personalizadas
Devolver entidades o un escalar resulta insuficiente. Necesitamos la capacidad de recoger cualquier resultado.
Imagina que escribimos una consulta JPQL cuya proyección —el conjunto de elementos declarados en la cláusula SELECT— no se corresponde con una entidad al completo. Además, las consultas solo deben obtener entidades cuando sea imprescindible. Aquí justifico este consejo.
¿Cómo lo conseguimos? Con un array de Object. Cada posición del array contiene un elemento de la proyección, de forma que se respeta el orden en el que aparece cada elemento en la SELECT.
Añadamos al repositorio un método que obtenga con JPQL un listado de países. En lugar de entidades Country, solo queremos el identificador y el nombre de cada país:
@Query("select c.id, c.name from Country c")
List<Object[]> findAllNamePopulation();
Array SELECT
(Long) [0] -> c.id
(String) [1] -> c.name
Funciona. Sin embargo, ¿ves el problema de esta técnica? Trabajar con el array será un fastidio. Menos mal que Spring nos ofrece dos alternativas más prácticas.
Proyección en constructor
Mira esta nueva versión del método anterior:
@Query("select new com.danielme.demo.springdatajpa.model.IdNameDTO(c.id, c.name) from Country c")
List<IdNameDTO> getAsIdNameDto();
IdNameDTO es esta clase:
package com.danielme.demo.springdatajpa.model;
public class IdNameDTO {
private Long id;
private String name;
public IdNameDTO(Long id, String name) {
super();
this.id = id;
this.name = name;
}
public Long getId() {
return id;
}
public String getName() {
return name;
}
}
Cualquier proyección puede recogerse en la clase o record que queramos, a condición de que posea el constructor idóneo. Este se indica en la SELECT con la opción NEW, y sus argumentos son los elementos de la proyección. No se requiere de ningún conversor o de configuración adicional alguna.
Esta proyección en constructor, capacidad de JPQL compatible con Spring Data JPA, también funciona con las consultas derivadas. Requiere que todos los nombres de los parámetros del constructor (la clase solo puede tener uno) coincidan con nombres de atributos de la clase de tipo entidad vinculada al repositorio. Por tanto, esta consulta derivada, que replica el comportamiento de la anterior, es válida:
List<IdNameDTO> findAsIdNameDtoBy();
Proyección en interfaz
Spring Data también nos da un elegante y cómodo sistema de proyecciones basado en interfaces. Para usarlo, crearemos una interfaz con métodos de tipo get para unos atributos «virtuales» cuyo nombre y tipo deben coincidir con los de los campos devueltos por la consulta.
Siguiendo con el ejemplo anterior, necesitamos una interfaz como la que sigue:
public interface IdNameProjection {
Long getId();
String getName();
}
Con ella, getAsIdNameDto puede reescribirse así:
@Query("select c.id as id, c.name as name from Country c")
List<IdNameProjection> getAsIdNameInterface();
Observa que hay que declarar los alias en la SELECT para establecer la relación entre la proyección y los getters de la interfaz.
De nuevo, estamos ante una funcionalidad compatible con las consultas derivadas. Exige que todos los getters de la interfaz se correspondan con atributos de la clase de entidad del repositorio. Puesto que IdNameProjection y Country satisfacen esta condición, podemos escribir lo siguiente:
List<IdNameProjection> findAsIdNameProjectionBy();
Tienes más información acerca de las proyecciones en el capítulo 7 del curso:
Ordenación
En las consultas derivadas puedes definir criterios de ordenación en el nombre del método con la palabra clave OrderBy. A ella le añades los atributos por los que efectuar la ordenación, indicando el sentido deseado: ascendente (Asc) o descendente (Desc).
Ejemplo de ordenación ascendente:
List<Country> findByPopulationGreaterThanOrderByPopulation(Integer population);
Si ordenas por un único campo de manera ascendente, puedes omitir la palabra Asc, de ahí que no la veas en el método anterior. No debería sorprendernos: la ordenación ascendente suele ser la predeterminada en la mayoría de las bases de datos y lenguajes de programación.
Caso distinto es el próximo ejemplo. Primero ordena los resultados por fecha de creación en sentido ascendente y luego por el nombre en sentido ascendente:
List<Country> findByPopulationGreaterThanOrderByCreationAscName(Integer population);
La palabra Asc que acompaña a Creation es imprescindible porque separa la declaración del atributo Creation de la declaración de Name. De hecho, sin ella el método no representa una consulta derivada válida.
Por supuesto, también puedes definir la ordenación dentro de una consulta JPQL:
@Query("select c from Country c where lower(c.name) like lower(:name) order by name")
List<Country> findByNameWithQuery(@Param("name") String name);
Tanto en las consultas derivadas como en las escritas con JPQL puedes establecer criterios de ordenación dinámicos con un objeto de la clase Sort. Permitamos criterios de ordenación dinámicos en el método findByNameWithQuery. Es tan sencillo como agregar un parámetro de tipo Sort:
@Query("select c from Country c where lower(c.name) like lower(:name)")
List<Country> findByNameWithQuery(@Param("name") String name, Sort sort);
¿Cómo se crea un Sort? Lo más fácil es recurrir a los métodos estáticos by de la propia clase
countryRepository.findByNameWithQuery("%i%", Sort.by(Sort.Direction.ASC,"name"));
Existe una sobrecarga de by que no recibe el sentido porque asume el sentido ascendente. En consecuencia, este código equivale al anterior:
countryRepository.findByNameWithQuery("%i%", Sort.by("name"));
En general, basta con especificar el sentido y los campos de ordenación en el orden que necesitemos. Si el sentido no fuera el mismo para todos los campos, crea varios Sort y combínalos en el orden idóneo con el método and:
Sort sort = Sort.by(Sort.Direction.DESC, "creation")
.and(Sort.by(Sort.Direction.ASC, "name"));
Paginación
La obtención paginada de datos se consigue de manera similar a la ordenación dinámica. Tenemos que definir los criterios de paginación en un objeto que añadimos como parámetro al método que ejecuta la consulta. En esta ocasión, el objeto es de la interfaz Pageable. Al igual que Sort, Pageable funciona con consultas derivadas y JPQL.
Además de los métodos de Pageable, el siguiente diagrama de clases muestra que Pageable incluye un Sort. Esta relación se debe a que la paginación precisa de un criterio de ordenación que garantice la coherencia del reparto de los datos entre las páginas. ¡Nunca pagines sin ordenar!

Si bien los métodos que emplean Pageable pueden retornar una lista, o cualquier estructura de datos contemplada por Spring Data JPA, lo más conveniente es devolver un Page. Además de una lista con el resultado, Page incluye información detallada sobre la página obtenida (número de página, elementos totales existentes, etc.). Lo habitual será que los clientes del método necesiten esa información para navegar por las páginas de datos. De la interfaz Slice, que también aparece en el siguiente diagrama, te hablaré en breve.

¡Manos a la obra! Así queda el método findByNameWithQuery con Page y Pageable:
@Query("select c from Country c where lower(c.name) like lower(?1)")
Page<Country> findByNameWithQuery(String name, Pageable page);
Para invocar a este método necesitamos un objeto Pageable. Lo creamos con los métodos estáticos of de la clase PageRequest. Les daremos el número de página solicitada (la primera es la cero), su tamaño y un objeto Sort. Este último puedes obviarlo si la consulta ya tiene un criterio de ordenación fijo.

Este es el ejemplo que encontrarás entre las pruebas del proyecto:
Page<Country> page0 = countryRepository.findByNameWithQuery("%i%",
PageRequest.of(0, 4, Sort.by(Sort.Direction.ASC,"name")));
assertEquals(4, page0.getTotalElements());
assertEquals(2, page0.getTotalPages());
assertEquals(COLOMBIA, page0.getContent().get(0).getName());
Devolver Page implica que la ejecución de findByNameWithQuery debe lanzar dos consultas SQL: la que obtiene los países y otra que cuenta los resultados totales con la función COUNT. Aquí tienes esas dos consultas:
select
country0_.id as id1_1_,
country0_.confederation_id as confeder5_1_,
country0_.creation as creation2_1_,
country0_.name as name3_1_,
country0_.population as populati4_1_
from
countries country0_
where
lower(country0_.name) like lower(?)
order by
country0_.name asc limit ?
select
count(country0_.id) as col_0_0_
from
countries country0_
where
lower(country0_.name) like lower(?)
Otra opción es devolver un Slice, la interfaz padre de Page que mencioné antes. La diferencia radica en que Slice no informa de los resultados totales. Por eso, carece de los métodos getTotalPages y getTotalElements, lo que evita la ejecución de la consulta de conteo.
Ahora que sabes cómo paginar, es el momento de recordar lo que señalé acerca del método CrudRepository#findAll. Evalúa siempre si necesitas emplear paginación en aquellas consultas que devuelvan múltiples resultados.
Operaciones de actualización
Con la anotación @Query también definimos sentencias JPQL de modificación de datos. Tres requisitos a tener en cuenta:
- El método debe estar anotado con
@Modifying. De lo contrario, Spring Data JPA interpretará que se trata de unaSELECTy la ejecutará como tal. - Se devolverá
voido un entero (int\Integer) que contendrá el número de registros afectados. - El método deberá ser transaccional o bien ser invocado desde otro, situado en un bean distinto, que sí lo sea.
Considerando estos puntos, voy a agregar a CountryRepository un método que actualiza las fechas de creación de todos los países según una dada:
@Transactional
@Modifying
@Query("UPDATE Country set creation = (?1)")
int updateCreation(LocalDateTime creation);
Las actualizaciones de tipo DELETE se pueden definir con una consulta derivada:
@Transactional
int deleteByName(String name);
El método devuelve el número de entidades eliminadas.
Este tipo de borrado recupera primero todas las entidades y luego las elimina de una en una, por lo que será un proceso lento si la cantidad de entidades a eliminar es elevada.
El borrado de todas las entidades con una única sentencia se consigue con JPQL:
@Transactional
@Modifying
@Query("delete from Country where id=:id")
int deleteCountryById(@Param("id") Long id);
Aunque esta segunda opción sea más eficiente, el borrado se efectúa directamente en la base de datos. Por esta razón, las entidades que ya estuvieran cargadas en los contextos de persistencia de JPA no se verán afectadas, luego Hibernate no ejecutará los métodos que atienden a los cambios de la entidad (@PreRemove, @PostRemove). Estas consideraciones también son válidas para las sentencias UPDATE.
Consultas SQL
Si bien es mucho lo que JPQL \ HQL permite expresar, a veces necesitaremos el poder del lenguaje SQL de la base de datos.
Ningún problema. Con @Query definimos consultas SQL si activamos la propiedad nativeQuery de la anotación. En JPA, a las consultas SQL se las conoce como consultas nativas.
Este método encuentra todos los países:
@Query(value = "select * from countries WHERE confederation_id = :confId", nativeQuery = true)
List<Country> findAllByConfederationNative(@Param("confId") Long confId);
La gran noticia es que casi todo lo que hemos visto funciona con las consultas nativas:
- Retorno de entidades del tipo del repositorio si la
SELECTdevuelve exactamente todos los campos de la entidad. De hecho, es el ejemplo anterior. - Retorno directo de un valor escalar, como una cadena, un número, un lógico…
- Uso de los argumentos del método como variables en la consulta, tanto con índices como con nombres.
- Proyecciones en interfaces.
- Ejecución de consultas SQL nombradas. En esta ocasión, la anotación es
@NamedNativeQuery. - Consultas
UPDATEyDELETEcon@Modifying.
No funciona:
- La ordenación con
Sort. Si la usas, verás un mensaje de error que no deja lugar a dudas: «cannot use native queries with dynamic sorting».
Funciona con matices:
- La paginación con
Pageable. Si devuelvesPagey la consulta que Spring Data JPA genera para contar todos los resultados fuera incorrecta (a veces ocurre), escribe la tuya propia propia encountQuery:
@Query(value = "select * from countries",
nativeQuery = true,
countQuery = "select count(*) from countries")
Page<Country> findAllNative(Pageable pageable);
La ordenación asociada a una configuración de paginación —el Sort contenido en PageRequest— sí funciona.
Page<Country> page0 = countryRepository.findAllNative(PageRequest.of(0, 3, Sort.by("name")));
- La proyección en constructor. Requiere configurar con
@SqlResultSetMappingla relación entre los elementos de laSELECTy el constructor. Esta configuración se aplica a una consulta nativa nombrada definida con@NamedNativeQuery:
@SqlResultSetMapping(
name = "idNameConstructor",
classes = @ConstructorResult(targetClass = IdNameDTO.class,
columns = {
@ColumnResult(name = "id", type = Long.class),
@ColumnResult(name = "name", type = String.class)}))
@NamedNativeQuery(
name = "Country.byPopulationNamedNativeQuery",
query = "select id, name FROM countries WHERE population > ?1",
resultSetMapping = "idNameConstructor")
public class Country {
@Query(nativeQuery = true)
List<IdNameDTO> byPopulationGreaterThanNamedNativeQuery(Integer population);
Como puedes ver, se requiere de cierta artesanía. Es más cómodo sacar partido a Spring Data y recurrir a la proyección en interfaz que ya conocemos:
@Query(value = "select id, name as name FROM countries WHERE population > :population", nativeQuery = true)
List<IdNameProjection> byPopulationGreaterThanProjectionNativeQuery(@Param("population") Integer population);
Como es habitual, encontrarás mucha más información y ejemplos en el curso:
Aprovecho para señalar que en Spring tienes la siguiente alternativa para ejecutar SQL sin Spring Data, JPA o Hibernate:
Probar el repositorio con tests automáticos
Escribamos varias pruebas, o tests, con JUnit 4 para testar las consultas del repositorio.
Antes de nada, revisa la conexión a la base de datos MySQL en el fichero db.properties:
jdbc.driverClassName = com.mysql.cj.jdbc.Driver
jdbc.username=user
jdbc.password=password
jdbc.url = jdbc:mysql://localhost:3307/countries
En la raíz del proyecto tienes un fichero Dockerfile y un script que configuran un servidor MySQL apropiado para la ejecución de los tests. Puedes generar la imagen y lanzar un contenedor de usar y tirar con estos comandos:
docker build -t spring-data-jpa-mysql . docker run --rm -d -p 3307:3306 spring-data-jpa-mysql
Más información sobre Docker:
Docker 1: introducción
Docker 2: imágenes y contenedores
Presta atención al puerto: podría entrar en conflicto con otro MySQL en ejecución. Por eso, he expuesto el puerto 3306 de MySQL a través del puerto 3307 del contenedor.
En cuanto al código, seré breve, ya que encontrarás todos los conocimientos requeridos en las publicaciones Testing con JUnit 4 y Spring: testing con JUnit 4.
Lo primero es añadir estas dos dependencias:
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>${spring.version}</version>
<scope>test</scope>
</dependency>
Debes declarar en la clase que contendrá las pruebas el runner SpringJUnit4ClassRunner. Su cometido es integrar Spring y JUnit 4. Arrancará Spring, permitiendo además la inyección de cualquier bean en la clase de prueba. La anotación @ContextConfiguration indica la configuración de Spring a usar.
Las pruebas se diseñarán para el juego de datos definido en el fichero /src/test/resources/dataset.sql. Contiene un script que Spring ejecutará antes de cada prueba gracias a la anotación @Sql.
En nuestro proyecto, todo lo anterior se refleja en esta clase:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = ApplicationContext.class)
@Sql("/dataset.sql")
public class CountryRepositoryTest {
@Autowired
private CountryRepository countryRepository;
La infraestructura está lista. Escribamos en CountryRepositoryTest las pruebas según ordena JUnit 4: en métodos públicos, sin retorno ni parámetros, marcados con @Test.
Aquí tienes la clase de prueba al completo:
package com.danielme.demo.springdatajpa.test;
import com.danielme.demo.springdatajpa.ApplicationContext;
import com.danielme.demo.springdatajpa.model.Country;
import com.danielme.demo.springdatajpa.model.IdNameDTO;
import com.danielme.demo.springdatajpa.model.IdNameProjection;
import com.danielme.demo.springdatajpa.repository.CountryRepository;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.jdbc.Sql;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.time.LocalDateTime;
import java.util.List;
import java.util.Optional;
import static org.junit.Assert.*;
@RunWith(SpringJUnit4ClassRunner.class)
//@ContextConfiguration("file:src/main/resources/applicationContext.xml")
@ContextConfiguration(classes = ApplicationContext.class)
@Sql("/dataset.sql")
public class CountryRepositoryTest {
private static final Long SPAIN_ID = 2L;
private static final Long MEXICO_ID = 3L;
private static final Long COLOMBIA_ID = 4L;
private static final Long CONCACAF_ID = 2L;
private static final String SPAIN = "Spain";
private static final String NORWAY = "Norway";
private static final String MEXICO = "Mexico";
private static final int MEXICO_POPULATION = 115296767;
private static final int ALL_COUNTRIES = 5;
@Autowired
private CountryRepository countryRepository;
@Test
public void testExistsByPopulationGreaterThan() {
assertFalse(countryRepository.existsByPopulationGreaterThan(150000000));
}
@Test
public void testFindByName() {
assertEquals(SPAIN, countryRepository.findNameById(SPAIN_ID).get());
}
@Test
public void testFindByNameContainingIgnoreCase() {
List<Country> countriesWithP = countryRepository.findByNameContainingIgnoreCase("p");
assertEquals(1, countriesWithP.size());
assertEquals(SPAIN_ID, countriesWithP.get(0).getId());
}
@Test
public void testFindByNameContainingIgnoreCaseAndConfederationId() {
List<Country> countries = countryRepository.findByNameContainingIgnoreCaseAndConfederationId("m", CONCACAF_ID);
assertEquals(1, countries.size());
assertEquals(MEXICO_ID, countries.get(0).getId());
}
@Test
public void testPopulation() {
assertEquals(3, countryRepository.countByPopulationGreaterThan(45000000));
assertEquals(3, countryRepository.findByPopulationGreaterThan(45000000).size());
}
@Test
public void testName() {
Optional<Country> optCountry = countryRepository.findByName(NORWAY);
assertTrue(optCountry.isPresent());
assertEquals(NORWAY, optCountry.get().getName());
}
@Test
public void testFindByConfederation() {
List<Country> countries = countryRepository.findByConfederationName("CONMEBOL");
assertEquals(1, countries.size());
assertEquals(COLOMBIA_ID, countries.get(0).getId());
}
@Test
public void testNoName() {
assertFalse(countryRepository.findByName("France").isPresent());
}
@Test
public void testNamedQuery() {
assertTrue(countryRepository.byPopulationNamedQuery(MEXICO_POPULATION).isPresent());
}
@Test
public void testNamedNativeQuery() {
IdNameDTO mexico = countryRepository.byPopulationNamedNativeQuery(MEXICO_POPULATION);
assertEquals(MEXICO_ID, mexico.getId());
assertEquals(MEXICO, mexico.getName());
}
@Test
public void testProjectionNativeQuery() {
IdNameProjection mexico = countryRepository.byPopulationProjectionNativeQuery(MEXICO_POPULATION);
assertEquals(MEXICO_ID, mexico.getId());
assertEquals(MEXICO, mexico.getName());
}
@Test
public void testQuerysSortingAndPaging() {
Page<Country> page0 = countryRepository.findByNameWithQuery("%i%",
PageRequest.of(0, 2, Sort.by(Sort.Direction.ASC, "name")));
assertEquals(4, page0.getTotalElements());
assertEquals(2, page0.getTotalPages());
assertEquals(COLOMBIA_ID, page0.getContent().get(0).getId());
}
@Test
public void testQuerysMultipleSorting() {
Sort sort = Sort.by(Sort.Direction.DESC, "creation")
.and(Sort.by(Sort.Direction.ASC, "name"));
List<Country> countries = countryRepository.findByNameWithQuery("%i%", sort);
assertEquals(SPAIN_ID, countries.get(0).getId());
}
@Test
public void testFindByPopulationGreaterThanOrderByPopulation() {
List<Country> countries = countryRepository.findByPopulationGreaterThanOrderByCreationAscName(0);
assertEquals(COLOMBIA_ID, countries.get(0).getId());
}
@Test
public void testUpdate() {
LocalDateTime creation = countryRepository.findByName(NORWAY).get().getCreation();
assertEquals(ALL_COUNTRIES, countryRepository.updateCreation(LocalDateTime.now()));
assertTrue(countryRepository.findByName(NORWAY).get().getCreation().isAfter(creation));
}
@Test
public void testDeleteByName() {
assertEquals(1, countryRepository.deleteByName(NORWAY));
}
@Test
public void testRemoveById() {
assertEquals(1, countryRepository.removeById(SPAIN_ID));
}
@Test
public void testRemoveByIdWithQuery() {
assertEquals(1, countryRepository.deleteCountryById(SPAIN_ID));
}
@Test
public void testProjectionConstructor() {
List<IdNameDTO> countries = countryRepository.findAsIdNameDtoBy();
assertEquals(ALL_COUNTRIES, countries.size());
}
@Test
public void testProjectionInterface() {
List<IdNameProjection> countries = countryRepository.getAsIdNameInterface();
assertEquals(ALL_COUNTRIES, countries.size());
}
@Test
public void testFindAllListNative() {
List<Country> countriesConcacaf = countryRepository.findAllByConfederationNative(CONCACAF_ID);
assertEquals(2, countriesConcacaf.size());
}
@Test
public void testFindAllPageNative() {
Page<Country> page0 = countryRepository.findAllNative(PageRequest.of(0, 3, Sort.by("name")));
assertEquals(ALL_COUNTRIES, page0.getTotalElements());
assertEquals(2, page0.getTotalPages());
}
@Test
public void testFindByCreationBetween() {
LocalDateTime startDate = LocalDateTime.of(2018, 10, 6, 18, 15);
List<Country> countriesBetweenDates = countryRepository.findByCreationBetween(startDate, LocalDateTime.now());
assertEquals(1, countriesBetweenDates.size());
assertEquals(SPAIN_ID, countriesBetweenDates.get(0).getId());
}
@Test
public void testFindByNameStartsWith() {
List<Country> countriesStartingS = countryRepository.findByNameStartingWithIgnoreCase("s");
assertEquals(1, countriesStartingS.size());
assertEquals(SPAIN_ID, countriesStartingS.get(0).getId());
}
@Test
public void testFindByNameNotStartsWith() {
List<Country> countries = countryRepository.findByConfederationIdNotIn(1L, 2L);
assertEquals(1, countries.size());
assertEquals(COLOMBIA_ID, countries.get(0).getId());
}
}
Conclusiones
¿Tenía o no razón cuando afirmé en la introducción que se necesita poquito para implementar la persistencia con Spring Data JPA? Nos centramos en la consulta, que es lo importante. Lo demás (paginación, ordenación, transformación de resultados, reemplazo de variables…) son tareas que Spring Data JPA asume con escasa o nula configuración por nuestra parte.
Las consultas más simples las resolvemos mediante consultas derivadas. Para las restantes recurrimos a JPQL\HQL y, en última instancia, al SQL de la base de datos. Con todos estos tipos de consultas trabajamos de forma parecida.
Reitero que este artículo es una breve introducción a los fundamentos de Spring Data JPA. Todos los asuntos abordados se estudian con profundidad en el curso. En él también descubrirás otras funcionalidades que te facilitarán la vida. Estas incluyen la escritura de consultas dinámicas sencillas con las tecnologías QBE, Criteria API y QueryDSL.
Código de ejemplo
El proyecto se encuentra en GitHub. Para más información sobre cómo utilizar GitHub, consulta este artículo. Incluye algunos de los ejemplos de procedimientos almacenados explicados en el capítulo 14 del curso.
Tutoriales relacionados
Introducción a Spring Boot: Aplicación Web con servicios REST y Spring Data JPA
Persistencia en BD con Spring: Integrando JPA, c3p0, Hibernate y EHCache
Testing en Spring Boot con JUnit 4\5. Mockito, MockMvc, REST Assured, bases de datos en memoria.
JPA con Hibernate: identificadores y claves primarias. Generación automática. Claves múltiples.

gracias por tomarte el tiempo para explicar este tipo de cosas, es de bastante ayuda encontrar este tipo de documentación cuando se está iniciando en Spring
me encanta este blog, gracias
@Query(«from Country c where lower(c.name) like lower(?1)»)
Country findByNameWithQuery(@Param(«name») String name);
donde se esta usando el param name ?
que no tendría que ser así
@Query(«from Country c where lower(c.name) like lower(:name)»)
Efectivamente, ya está corregido. Gracias por avisar!!
Muchas gracias por tu tiempo para explicar este tema. Saludos
Excelente integración de conocimientos en un solo articulo. Felicitaciones!